
2025年春节,深度求索 DeepSeek 突然火遍全球。

这又引起了我的兴趣,以前使用过国外的 AI 绘画工具,我当然要去体验一把 DeepSeek 大语言模型的实力。
我问了一个关于我本人的问题,哈哈哈,竟然还挺了解我:






—— DeepSeek 回答 ——
问题:介绍一下摄影师公子老白和作品,他的获奖记录
DeepSeek:
已搜索到 27 个网页
已深度思考(用时 14 秒)
嗯,用户让我介绍一下摄影师公子老白和他的作品,还有获奖记录。让我先看看搜索结果里的信息。首先,网页2、5、6、8提到了公子老白的摄影作品和活动。网页2是他的个人网站,里面有年度和专辑的分类,比如春、夏、秋、冬等,还有扫海、星空这些专辑,说明他的作品主题多样。网页5的相册部分有很多专辑,比如内蒙古、徽州、西藏,这些可能都是他的主要拍摄地。
然后,关于获奖记录,网页3和网页8提到了他在2019年获得过几个摄影比赛的小奖,不过具体的奖项名称没有详细说明。网页8的2019年回顾里提到他多次外出拍摄,并且有比赛名次,但同样没有具体奖项。需要确认是否有其他网页提到更详细的获奖情况,但搜索结果里可能没有。网页7和10提到的老白似乎是指艾美奖的演员或者白酒品牌,应该不相关,所以可以排除。
接下来,他的背景信息,网页9显示他在蜂鸟网注册于2011年,地区未知,但网页2提到他来自上海,是风光摄影爱好者。网页3和8的博客内容显示他经常去各地采风,比如大连、温州、新疆等,并且有丰富的拍摄经历。
作品方面,网页5的相册里有大量专辑,包括内蒙古、西藏、魔都魅影等,每个专辑有几十到上百张照片。此外,网页6的博客有关于器材测试和摄影技巧的文章,比如索尼相机的设置和镜头评测,说明他对器材也有研究。
总结的话,公子老白是来自上海的风光摄影师,作品涵盖自然风光和城市景观,多次在摄影比赛中获奖,但具体奖项名称未明确。他的摄影风格注重自然与人文结合,经常在博客分享拍摄经历和技巧。需要将这些信息整合,分点回答,并引用对应的网页作为来源。
摄影师公子老白(网名)是中国上海的一位风光摄影爱好者,其作品以自然风光、城市景观和人文纪实为主,足迹遍布全国多地。以下是关于他及其作品的综合介绍:
一、个人背景与摄影风格
1.背景与定位
公子老白自2011年起活跃于摄影社区蜂鸟网,注册地为上海,专注于风光摄影创作。他自述“对摄影的狂爱”驱动其频繁外出拍摄,尤其热衷于探索山川、海岸、星空等自然场景,同时兼顾城市景观(如上海“魔都魅影”)。
2.摄影风格
他的作品以 壮阔的自然风光 和 细腻的光影捕捉 见长,注重展现季节变化与地域特色。例如:
内蒙古草原:通过“万马奔腾”“冬季坝上”等主题呈现草原的四季风貌。
徽州与皖南:以古村落、山水田园为背景,强调诗意与人文气息。
星空与延时摄影:尝试拍摄银河与延时作品,自嘲此类创作“娱乐为主”,但仍追求技术突破。
二、代表作品与创作主题
1.地域专辑
公子老白的作品按地域分类,形成多个系列专辑,涵盖中国多地风光:
内蒙古:锡林郭勒盟、呼伦贝尔等地的草原与金秋景象。
西藏:山南、日喀则地区的雪山与高原湖泊。
沿海景观:大连萤光海、浙江渔山列岛等地的海蚀地貌与海洋主题。
江南与古镇:如苏州黎里古镇、安徽歙县等地的水乡与人文纪实。
2.季节与专题
他长期追踪四季变化,推出“春”“夏”“秋”“冬”系列,并创作“扫海”“星空”等专题,展现自然动态之美。
三、获奖记录与摄影成就
1.比赛奖项
根据其博客自述,2019年是公子老白摄影成果丰硕的一年,他提到“获了几个摄影比赛小奖”,但未具体说明奖项名称。这一年他完成了15次外出拍摄,足迹包括新疆伊犁、福建漳平、广西涠洲岛等地,作品在比赛中获得认可。
2.行业认可
其摄影技术受到同行关注,尤其在器材评测(如索尼微单设置、唯卓仕镜头测试)和后期教程分享(如Snapseed使用)方面具有一定影响力。
四、创作理念与公众互动
1.理念与态度
他强调摄影的“热爱与疯狂”,认为拍摄不仅是记录,更是对自然美的感知与表达。例如,他在西藏拍摄时感叹“原始之美有待继续发掘”,体现了对自然景观的敬畏与探索欲。
2.分享与交流
通过个人网站和博客持续更新作品与拍摄经历,并开设“摄影旅程趣事”专栏,以轻松笔触记录采风中的故事(如新疆拍摄时因高强度行程集体补觉)。
总结
公子老白作为非职业摄影师,以高度的热情和丰富的创作实践,在风光摄影领域积累了独特视角与代表性作品。尽管具体奖项信息有限,但其作品通过线上平台广泛传播,成为自然与人文摄影爱好者交流的范例。如需进一步了解其作品,可访问其个人网站公子老白摄影或博客专题页面。
—— 引用结束 ——
这个结果相当的厉害了,问题理解、搜索查找、资料分析、文案撰写都非常强大!
同样的问题,我又问了一下 Kimi,结果也非常满意,答案侧重点不同,有些内容更详细:


—— Kimi 回答 ——
问题:介绍一下摄影师公子老白和作品,他的获奖记录
Kimi:
已阅读 46 个网页
公子老白是一位来自中国上海的风光摄影爱好者,他的作品风格多样,涵盖了自然风光、城市景观以及星空等多个主题。他的摄影作品展现了对光影、色彩和构图的深刻理解,能够通过镜头捕捉到大自然的壮美与宁静。
代表作品
《峡谷夜色》:该作品入选了游侠客摄影网2019年风光组TOP10,展现了峡谷在夜色中的神秘与宁静。
《安集海大峡谷》:这张照片获得了《一汽马自达摄影大赛“寻访最美风景·潮奢新解”》优秀奖。
《果子沟大桥》:该作品入围了《70周年摄影大赛》,并获得了《像素蜜蜂「#桥 标签挑战赛」》一等奖。
《阿克塔斯草原》:这张照片获得了《艺术风光摄影大赛》三等奖。
获奖记录
以下是公子老白的部分获奖记录:
2019年:
《大扬2021年1月“极简主义”主题月赛》三等奖
《大杨影像9月“极致光影”主题月赛》优秀奖
《最美福州拍摄角度》二等奖
《70周年摄影大赛》入围
《像素蜜蜂「#桥 标签挑战赛」》一等奖
《艺术风光摄影大赛》三等奖
《像素蜜蜂「#星空 标签挑战赛」》优秀奖
《一汽马自达摄影大赛“寻访最美风景·潮奢新解”》优秀奖
《“大扬杯”第六届《海峡摄影》2月“航拍视角”主题月赛》二等奖
《“安逸四川”系列作品征集活动》三等奖
《大杨影像9月“极致光影”主题月赛》三等奖
《大杨影像11月“古建筑之美”主题月赛》二等奖
《“湛卢杯”第27届福建省摄影展》风光类入选
公子老白的作品不仅展现了他对摄影的热爱,也体现了他在风光摄影领域的专业素养和艺术追求。他的作品多次在各类摄影比赛中获奖,证明了他的实力和影响力。
—— 引用结束 ——
这二年在 AI 人工智能方面,国内厂商进步神速,我先后试用过:深度求索的 DeepSeek、月之暗面的 Kimi、阿里云的 通义、字节跳动的 豆包、剪映的 即梦、快手的 可灵(都有网站和 APP ),国外的 Midjourney 以前使用过,整体感觉都挺好用。
我还重点试用了一下通义的“文字作画”、“文生视频”、“图生视频”功能,很强大,基本能满足我的需求。
以下是使用通义“文字作画”的过程及结果:
文字描述如下:
摄影纪实风格,超广角镜头效果,在山谷里的小溪旁,草地上野花盛开,小溪及溪边的鲜花做前景,中景是一片树林,树木高大笔直,远处是雄伟的雪山,日落十分,满天晚霞,雪山出现日照金顶。高清晰,透视强烈。
再用智能扩写,扩写为更加详细的描述,然后生成作画,结果如下:




我的天啊!这比我拍得都好!这个结果可以媲美 Midjourney。对于生成卡通人物形象,我还是喜欢 Midjourney 的结果。
“文生视频”过程基本一样,但只能生成 5 秒钟视频,试验结果如下:
使用智能扩写后的描述为:
纪实摄影风格,日落时分,一位专业摄影师沉浸在山林的怀抱中。他身穿防风外套,头戴宽边帽,正全神贯注地操作着一台高端单反相机,镜头对准了满天绚烂的彩云。摄影师的表情兴奋而专注,仿佛能感受到每一缕光线的变化。随着快门的每一次按下,空气中都弥漫着创造的喜悦。拍摄完毕,他转身向身旁的朋友展示刚捕捉到的美景,两人围在一起,通过相机屏幕欣赏这大自然的杰作,脸上洋溢着满足和惊叹。背景是渐渐暗淡的山林,远处的山峰被夕阳染成了金色。采用广角镜头,捕捉这一刻的壮丽与温馨。
“图生视频”功能也非常强,下图是一张泰国拍摄的夜市乐队照片,看看能生成什么样的视频?

这真是 AI 生成的吗?毫无违和感!
又以卡通人物试验,使用“图生视频”功能生成了几段视频,并剪辑在一起,这也太真实了,各种表情非常到位:
2025年1月28日凌晨,DeepSeek 又发布了多模态模型 Janus-Pro,进军文生图领域。
我开始以为也只是“文生图”的应用,当我试用了以后,发现还有一个更牛的功能:“多模态理解”。
说人话就是 AI 能看懂你的照片。
试用网站:https://januspro.org
“Multimodal Understanding 多模态理解”看看它有多牛?


—— Janus-Pro 回答 ——
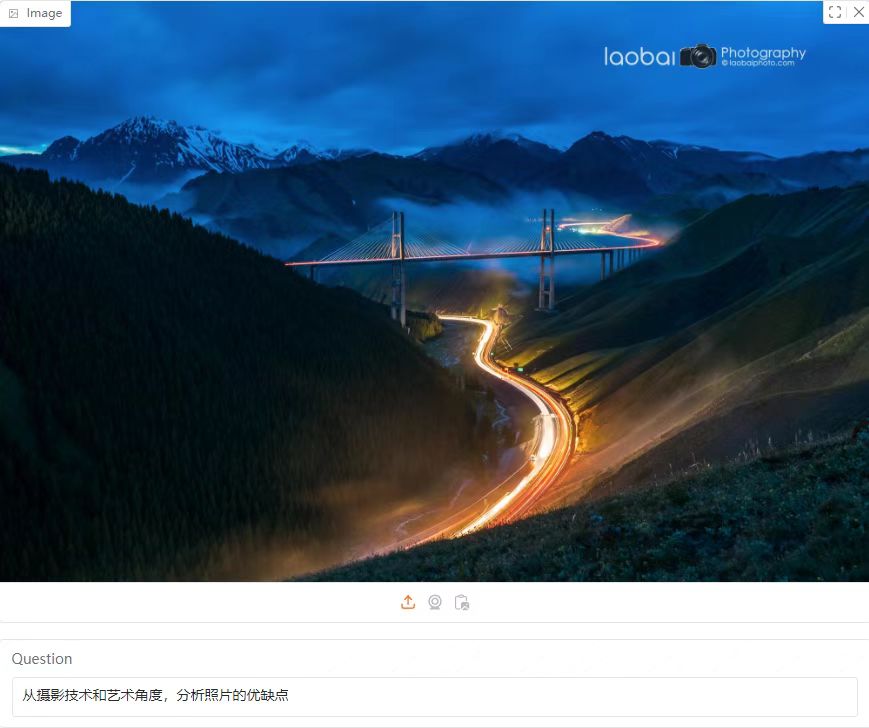
问题:从摄影技术和艺术角度,分析照片的优缺点
Janus-Pro:
这张照片展现了壮丽的自然景观和人类工程的结合,从摄影技术和艺术角度来看,有以下优缺点:
优点:
1.光轨效果
照片中明显可见的长时间曝光光轨效果,增加了动态感,使静态的风景显得更加生动。
光轨的弯曲方向与道路的曲线相呼应,增强了画面的整体协调性。
2.色彩与氛围
深蓝色的天空和远处的雪山形成了强烈的对比,营造出一种宁静而神秘的氛围。
夜晚的灯光与自然景观的结合,使画面既富有现代感,又保留了自然的原始之美。
3.构图与平衡
桥梁和光轨的布局使画面具有良好的纵深感,从前景到背景层次分明。
山脉、桥梁和光轨的分布均衡,使画面既稳定又富有变化。
4.细节与对比
远处的雪山、近处的森林和道路上的光轨形成了丰富的细节,使画面更加饱满。
光轨与自然景观的对比,突出了人类工程与自然环境的和谐共存。
缺点:
1.曝光时间可能过长
长时间曝光可能导致画面中的光轨显得过于明亮,而周围环境的光线可能被过度曝光,导致细节丢失。
2.可能的噪点
长时间曝光容易产生噪点,尤其是在低光环境下,这可能会影响画面的清晰度和细节。
3.天气条件的影响
如果拍摄时天气不稳定,如风或雨,可能会影响光轨的稳定性,导致画面出现模糊或不均匀的光轨。
4.构图中的局限性
虽然构图平衡,但桥梁的中心位置可能略显单调,如果能够通过其他元素(如云层或山峰)增加视觉焦点,可能会使画面更加引人注目。
总结:
这张照片在光轨效果、色彩和构图方面表现出色,展现了自然与人类工程的和谐美。然而,长时间曝光可能带来的光轨过亮、噪点等问题需要通过后期处理或调整拍摄参数来解决。此外,通过增加其他视觉元素,
—— 引用结束 ——
这也太强了吧!以后又多了一位会欣赏我摄影作品的 AI 观众了。
也试了一下“Text-to-Image Generation 文字生成图片”功能,用刚才同样的描述文字生成图片,还差一点意思,可能是分辨率太低。




对于 AI 的试用,我也仅仅局限于此,是最皮毛的基础应用,据我所知,AI 写文案、写 PPT、编程、修图等等很多方面,都已经非常智能了,而我从未涉及过,但就粗浅的试用也感受到:AI 人工智能的发展,已经超出了我的预期,前途不可限量,同时也带来了不少担忧……
补充:
最新消息:2025年2月6日,字节跳动数字人团队推出了新的多模态数字人方案 OmniHuman,其可以对任意尺寸和人物占比的单张图片结合一段输入的音频进行视频生成,生成的人物视频效果生动,具有非常高的自然度。(只找到新闻稿,未找到试用网站,放上几段官方演示视频)
请参考:https://omnihuman-lab.github.io